虛擬化集中化帶來了管理上方便、資源的集中以及整體硬體設備成本降低
但是隨之而來的問題,就是資料會非常非常重要 !一旦這個雞蛋籃子破了,後果不堪設想
(這篇文章就是要來討論如果籃子破了怎樣撈蛋汁跟蛋黃)
一般而言,在虛擬化規劃內,會有主機HA 跟Storage replication
當然若有再一個備份Agent與異地備援更理想。
案例分享
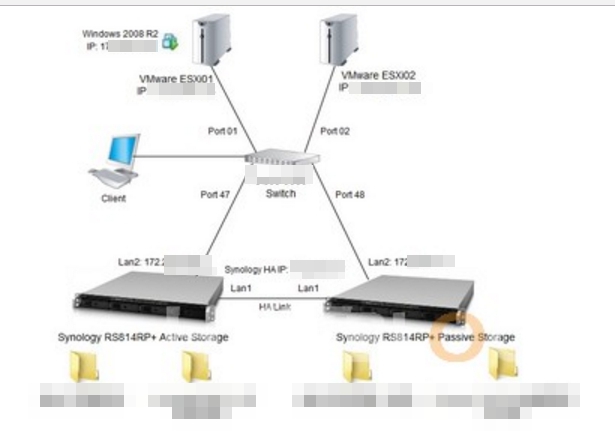
▲上圖為客戶虛擬化架構
架構分析
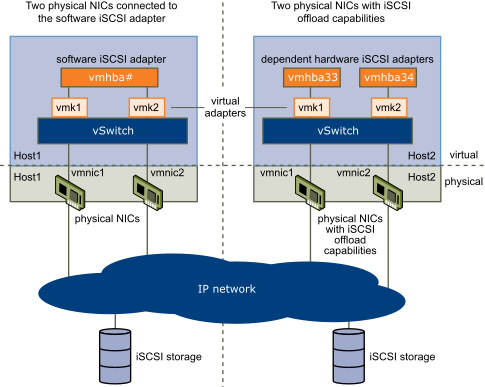
HyperVisor 是用 VMware ESXi 5.1 兩台 Synology DSXXX做Storage Server
這邊客戶用上了 Synology High Availability 來保持在NAS內的資料與iscsi Lun的同步
想要對Synology High Availability 實用狀況更瞭解可以參考這
Synology High Availability 功能應該是靠DRBD套件實現 , 客戶這樣規劃與設計也沒有不妥當
資料遺失狀況
狀況是客戶在進行年度保養維護的時候停電,可能是沒留意到 VM 是否還在存取的情況下,就先把 Storage 關機,
再去關閉 Hyperviosr esxi,當再次開機之後,VMFS Datastore 已經損毀,無任何VM檔案存在。
- SI 有針對二個node lun個別掛載Lun , 但二個Lun esx 系統,都無法辨識Volumne。
- IQN Name 有無變化等也找過。
- VMware上有一堆KB (Knowledge Base) VMFS Undelete 也無解
- 詢求過 Synology FAE Support 無解。
OSSLab收件救援
檢查機器狀況
送到本實驗室來
先檢查儲存Server硬體狀況:
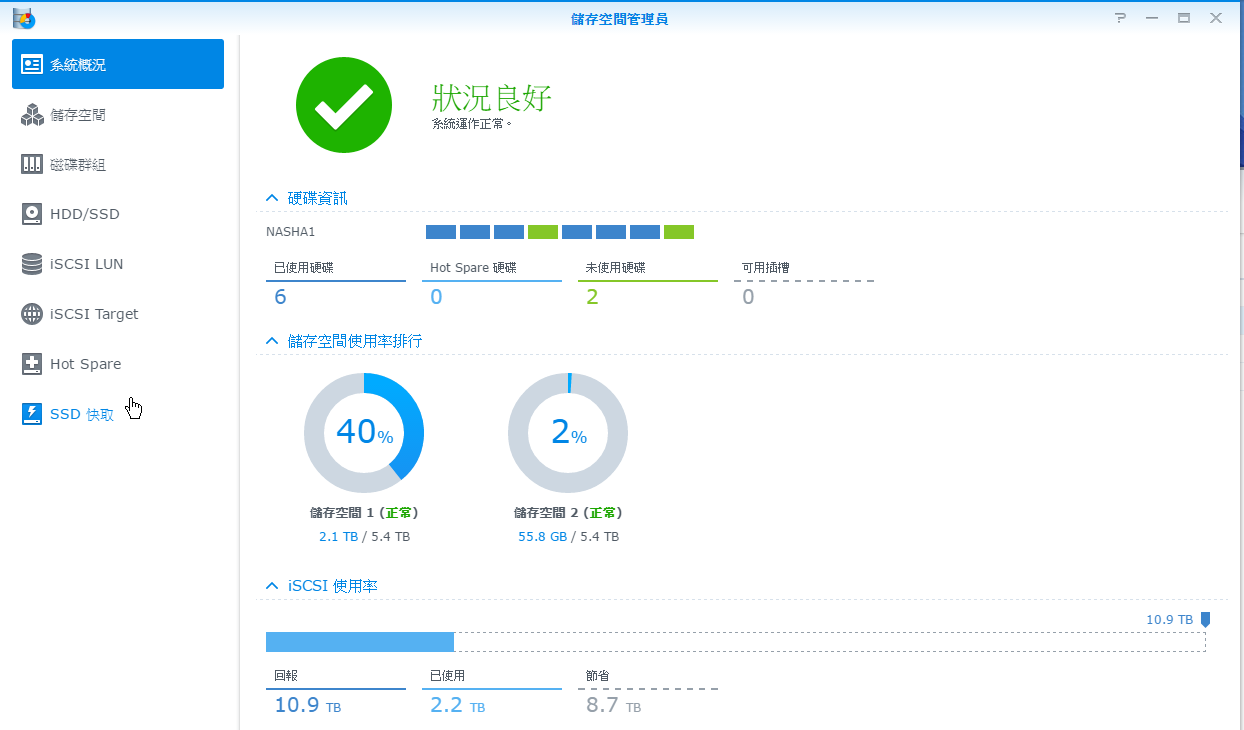
再檢查Raid 結構看似正常 (客戶也沒做過 Rebuild動作)
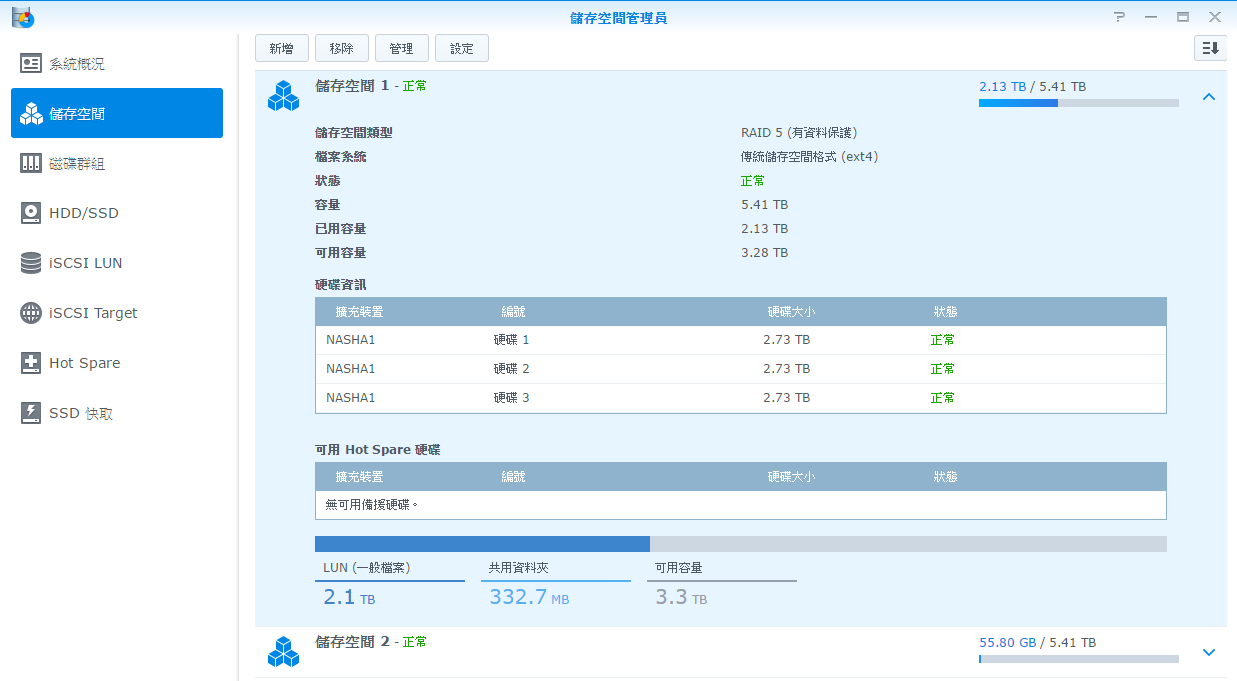
硬碟健康狀況正常
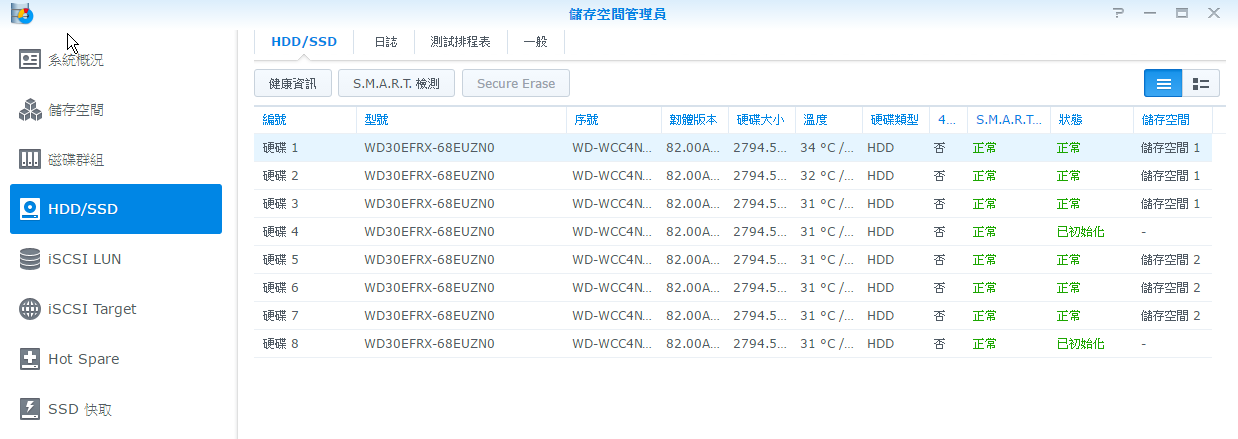
這台機器有 8 個槽,全部使用 WD 3TB 構成,每四顆作為一組成為兩個陣列,每個陣列是使用三顆硬碟做 RAID 5,以及一顆做備援。
iSCSI Lun image 檔案完整度”看似”正常
客戶用的是 iSCSI Lun (Regular img File ) 也就是說iSCSI Lun存在NAS 檔案層系統上的 Image File
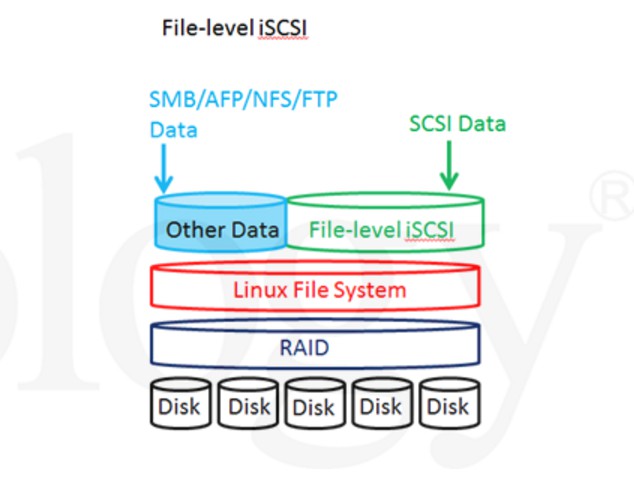
要得到最上層的資料 File level 的iSCSI Data 跟 ohter Data 必須要滿足下面條件:
- 硬碟無物理與韌體上損壞. 扇區讀取正常
- Storage Pool (Raid 順序 、排列方法、 stripe size ) 都是正確的
- NAS 檔案層 (ext4 or Btrfs) 要正常
- iSCSI img File 結構要正常
- VMDK檔案結構也要正常
這狀況推測 iSCSI Lun 內VMFS 分區跟檔案系統損壞的問題
更深入瞭解請參考OSSLab的演講 架構儲存虛擬化合一與企業級儲存救援
準備救援
開始準備恢復方法
一般來說,這iSCSI image file放在 “/volume1/@iSCSITrg/”.
在不改變客戶原有Storage設定與環境下 (假設客戶的Storage 有部分資料還是好的,日後還要上線這很重要)
先把 iscsi target 掛載起來(此圖已經屏蔽 iSCSI iqn Name)
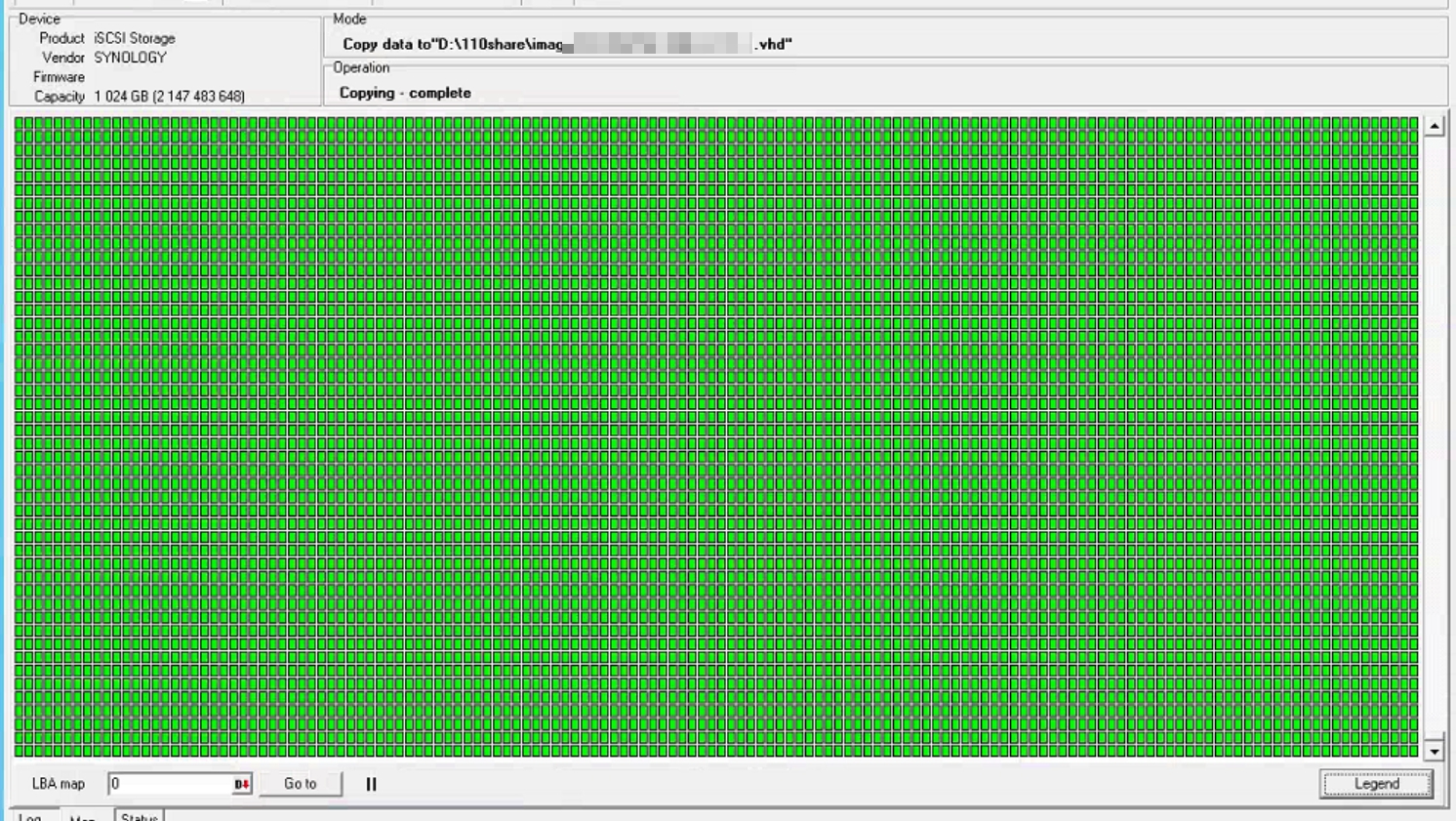
掛載後最重要的事情 先DD (鏡像全扇區) iscsi Lun
恢復虛擬化架構資料,會考慮到三種成果
- 整個 Lun 都還可mount ,裡面的分區跟FS (VMDK檔案也都正常 )
- 重要的VM 檔案都還在, VM還可正常Boot
- 前二種都無法成功,只能用Raw Recovery 技術撈出 VMDK裡的檔案 ,能拿回多少就多少
救援結果
由於現在客戶大部分在iSCSI Lun 與VMFS 層都有做thin provisioning.對於現有的資料救援軟體成功率都是偏低的…
網路上也沒VMFS文件系統敘述,這該怎辦?
Use The Force Luke !(可以用正念波還原資料嗎?)

只能讀各路神人不知道怎寫出來的工具原始碼 VMFS TooL 改寫跳過檢查完整性方式,用Cygwin 編譯
(閱讀原始碼後 會發現 VMFS 基本上就是EXT4 +LVM的修改版)
提取VMDK (跳過 vSphere On-disk Metadata Analyze)
讓自己程式盡量Mount. OK開始提取資料
VM驗收 (列舉其中一台)
結論–處理方針
怎麼做可以避免這樣的問題發生,或是真的發生了該怎樣解,或是減輕費用的支出,我們歸納出幾個要點:
1. 備份的策略要更完備
原本客戶的環境是有做HA,但是很明顯的在某種情況的故障之下,這個架構是無效的,那就要更小心做好備份規劃,在這個案例中能改善的像是:
- 虛擬機器的多重快照備份
- 再多一個獨立儲存設備做第二份備份
- 異地或雲端空間的備份(可參考虛擬化與雲端備份整合)
2. 資料恢復手段只能留做最後手段,但當災難發生時候 如果發現備份的資料不對 或是太舊 若想要保有原資料請盡量保持原儲存裝置狀況,不要自行做任何處理。
像是新增或修改LUN, FSCK Rebuild VMware 某些KB 方法等..動到檔案層結構都有風險,要做這些動作前,請先對最底層Storage做快照,無法快照就要對Storage Pool做DD (鏡像全部扇區),不然處理過後,會大幅度拉高資料救援成本並可能造成救回的資料再也無法挽回。
3. 要找怎樣的資料救援公司,在這個案例中,至少要有以下幾個要點:
- 要有完整的設備:
硬碟救援設備 PC3000 MRT 、完整硬碟材料庫 、訂製光纖轉卡、 10G 網路服務器 、虛擬化實驗室、超大儲存空間,這樣處理每個層面儲存裝置的問題。 - 了解陣列、檔案系統結構、虛擬化架構 :才能第一時間的處置跟該救援什麼樣的資料,也才能對未公開檔案格式(如VMFS)做逆向推測 ,
最終要驗證救出來的資料是否可用…等。 - 受過專業援技術訓練


