
SSD 可以做資料救援嗎?
我們來看看資安密碼學專家 Philipp Gühring 因為自用的三星 EVO 840 250GB SSD 故障,因此對SSD 基於底層原理開始做故障原因分析
本篇為目前唯一 公開的逆向SSD內核工作與嘗試資料救援資訊 。
這篇文章的思路 點出了 如何對當代embedded system 維修逆向推測思考
1.從電子零件規格分析
2.從電壓分析硬體是否可能有物理損壞
3.從embedded 升級韌體程式分析
4.從JTAG下手分析指令與記憶體.
5.從I2C, SATA通訊協議分析(雖然這次他沒使用SATA 邏輯分析儀)
6.瞭解整個啟動流程,以打斷流程方式來修復啟動失敗的embedded system .
非常值得我們學習這種探究態度
OSSLab結合本身實務經驗與原廠一手技術資源來補充 說明探究SSD故障分析及資料恢復原理
2018 4月更新
http://www2.futureware.at/~philipp/ssd/TheMissingManual.pdf
故障SSD在OS下的錯誤表徵
範例中的故障的EVO 840 250GB SSD
以下這故障 SSD 在 Linux 下使用 dmesg 得到的資訊:
[ 1.203395] ahci-imx 2200000.sata: fsl,transmit-level-mV value 1025, using 00000024 [ 1.203432] ahci-imx 2200000.sata: fsl,transmit-boost-mdB value 0, using 00000000 [ 1.203464] ahci-imx 2200000.sata: fsl,transmit-atten-16ths value 8, using 00002800 [ 1.203494] ahci-imx 2200000.sata: fsl,receive-eq-mdB not specified, using 05000000 [ 1.203543] ahci-imx 2200000.sata: Looking up target-supply from device tree [ 1.206436] ahci-imx 2200000.sata: SSS flag set, parallel bus scan disabled [ 1.206494] ahci-imx 2200000.sata: AHCI 0001.0300 32 slots 1 ports 3 Gbps 0x1 impl platform mode [ 1.206531] ahci-imx 2200000.sata: flags: ncq sntf stag pm led clo only pmp pio slum part ccc apst [ 1.208050] scsi host0: ahci_platform [ 1.208473] ata1: SATA max UDMA/133 mmio [mem 0x02200000-0x02203fff] port 0x100 irq 71 [...] [ 6.592593] ata1: link is slow to respond, please be patient (ready=0) [ 11.212587] ata1: COMRESET failed (errno=-16) [ 16.602585] ata1: link is slow to respond, please be patient (ready=0) [ 21.222578] ata1: COMRESET failed (errno=-16) [ 26.612582] ata1: link is slow to respond, please be patient (ready=0) [ 56.252588] ata1: COMRESET failed (errno=-16) [ 56.261143] ata1: limiting SATA link speed to 1.5 Gbps [ 61.292587] ata1: COMRESET failed (errno=-16) [ 61.301345] ata1: reset failed, giving up [ 61.310158] ahci-imx 2200000.sata: no device found, disabling link. [ 61.319008] ahci-imx 2200000.sata: pass ahci_imx..hotplug=1 to enable hotplug
這邊可以看到電腦的SATA 端口對 嘗試著用 COMRESET 做初始化(1.206531 秒至 1.208473之間),但它一直沒有接收到 SSD 應該給的 COMINIT 的回應。5 秒之後在 6.592593 秒時還是沒有回應,在一分鐘後的61.301345秒時它放棄了。理論上 COMINIT 要在 COMRESET 的一秒內有回應。
如果你對 SATA 的協定有興趣:
http://de.slideshare.net/niravdesai7121/sata-protocol
第三十頁可以看到 COMRESET 與 COMINIT 的時差,電腦端的 SATA 發出COMRESET,SSD應該要回應COMINIT。SATA訊號才會Ready 。
。
PCB上的 IC與電子元件分析
在由實體開始解析。
打開外殼後 Samsung SSD PCB 如圖.

上面一長條的是 SATA 接口,左下角正方形的是控制器 CPU,中間的是 SDRAM,右邊的是真正的 NAND 快閃儲存晶片
背面則是第二顆 NAND 快閃晶片在同樣的位置(推測這樣比較好布線,或許是分享同樣的data bus)
控制器 CPU 稱做 Samsung MEX (PN是S4LN045X01-8030),它有3個ARMv7-r Cortex R4 400MHz 核心。
以下為控制器CPU上面文字:
SAMSUNG S4LN045X01-8030
N7Y89MMB
U1441 ARM → 1441 代表它是2014年41週出廠的
主控與SSD Flash Bank關聯如下
http://www.cactus-tech.com/en/resources/blog/details/solid-state-drive-primer-8-controllerarchitecture- channels-and-banks
SDRAM 晶片:
Samsung 512 MB Low Power DDR2 SDRAM
Samsung, 4Gb, LPDDR2 SDRAM, 1CH x 32, 8 banks, 134-FBGA, MONO, 1066Mbps, 1.8V/1.2V/1.2V:
512MB LPDDR2 DRAM:
一樣是IC上面文字敘述:
SAMSUNG 440
K4P4G324EQ-FGC2
K:=Memory
4:=DRAM
P:=LPDDR2 (guess)
4G:=4G, 8K/64ms Density
32:=x32 Bit Organisation
4:=8 internal Banks
E:=Interface ?
Q:=SSTL-2 1.8V VDD, 1.8V VDDQ
-F:=7th Generation
G:=FBGA Package
C:=Commercial, Normal Temperature&Power range (0-95°C)
EXH382HCC
NAND晶片是真正保留資料的地方:
NAND TLC 128 GB: (19nm Toggle Mode 2.0 TLC (3-bit per cell) NAND (Model# K90KGY8S7M-CCK0))
SAMSUNG 440
K90KGY8S7M-CCK0
K:=Memory
9:=NAND Flash 0:=3-Bit MLC (TLC)
KG=128G Y8=Organisation x8?
S=Voltage ?
7=Mode ?
M=1st Generation
C=CHIP BIZ D : 63-TBGA
C=Commercial, Normal(0°C-95°C) & Normal Power
K=Customer Bad Block ?
0=Pre-Program Version:None
想要更瞭解Samsung產品命名型號 可以參考這份文件。
http://www.samsung.com/global/business/semiconductor/file/media/SamsungPSG_july2010_final- 2.pdf
第16頁
PCB上還有一些小晶片,JS4TAA 與 AKE4QD,”ABS 431.WD”,還有個名為”GUILL TI 48″的晶片,這是德州儀器製造的。
基於 這也是硬碟上的通用元件 ,Hddguru 的 fzabkar 大神指出了這些電子零組件:
Js4TAA 是一個由 STMicroelectronics 5V STEF4S 電路保險絲。”JS4″代表零件號碼中重要的編號。GUILL是個由德州儀器所製造的 TPS62130D2 同步下降 DC-DC 轉換器。AKE40D 代表一個多重輸出模式切換的DC-DC轉換器,或許有整合電路序列,”AKE” 代表零件號碼中重要的編號。
推斷 ABS 零件是個 I2C 裝置,我現在猜測他是個感溫元件。類似以下這些
http://www.ti.com/lit/ds/symlink/tmp275.pdf
http://www.nxp.com/documents/data_sheet/LM75A.pdf
http://ww1.microchip.com/downloads/en/DeviceDoc/25095A.pdf
用邏輯分析儀 記錄了以下的 I2C 通訊:
I2C
Time,Dir,ID,Data,ACKed,
1.0870288E-01,Write,18,08 02,Y,
1.0890320E-01,Write,18,00,Y,
1.0903376E-01,Read,18,00 77,N,
1.0923408E-01,Write,18,01 02 29,Y,
1.0949680E-01,Write,18,04 05 50,Y,
1.0975952E-01,Write,18,04,Y,
1.0989008E-01,Read,18,05 50,N,
1.1008976E-01,Write,18,02 05 00,Y,
1.1035280E-01,Write,18,02,Y,
1.1048336E-01,Read,18,05 00,N,
1.1068304E-01,Write,18,03 04 B0,Y,
1.1094608E-01,Write,18,03,Y,
1.1107664E-01,Read,18,04 B0,N,
在三星SSD上,ABS元件或類似的晶片總是接近快閃晶片旁,看起來應該是測量Flash溫度。
找到以下這份文件解釋了三星的溫度管理策略,在第十三頁開始:
http://www.samsung.com/semiconductor/minisite/ssd/downloads/document/Samsung_SSD_950_P RO_White_paper.pdf
硬體有沒有問題?
SSD 需要電力供電,這一顆需要透過 SATA 埠供電。
要來判定硬體電路與IC有沒有問題最簡單的小學生方法: 拿好的來比對 通電後測試IC跟元件電壓
先找出一個好的 SSD,做電路測量,然後在損壞的 SSD 上做比對,電壓都正常。
基於電源正常 有很大的機會不是硬體損壞。
下圖為本案例實測後的電壓圖,測試方法 一端先接GND ,先轉三用電表導通檔位,不要找直接互通的 ,記錄出可測良點 ,再轉測量電壓檔位,再一一測試可測量點的電壓。


這邊有清晰的大圖連結:
http://www2.futureware.at/~philipp/ssd/SamsungEVO840Voltages.pdf
Safe Mode
OSSLab 購買PC-3000 SSD資料救援設備
http://www.acelaboratory.com/pc3000-SSD.php。
設備的視訊教學跟說明書都有提到 Samsung SSD 有個安全模式,短路 SSD PCB 上兩個特定針腳後,然後將 SSD 通電,使 SSD 進入“安全模式”。
http://blog.acelaboratory.com/pc-3000-ssd-samsung-family.html
從硬碟的領域來講,安全模式表示硬碟不會啟動電機馬達來實際讀/寫硬碟,當在SSD時,是在NAND沒有任何電源安全風險的情況下與硬碟控制器晶片通訊。
經過使用安全模式,發現它代表著下面一些狀況:
*只有啟動第一個核心 mex1,mex2 和 mex3 在 SAFE模式下沒有通電,這表示在正常(非安全)模式下,mex1 可能在初始化結束的某個步驟負責喚醒 mex2 和 mex3。
*SSD 顯示只有 512 MB,不再是 250 GB,這類似於 SSD 中的 RAM 大小,所以這種方式很可能是直接存取 RAM。讀取任何東西並沒有提供任何原始的內容,所以它似乎沒有掛載快閃記憶體,快閃記憶體的加密沒有執行
*它總是顯示序列號SN000000000000,所以它看起來是試著不從設置讀取任何東西,所以它不會在初始化期間由於組態記憶體中的有垃圾資料而當機。
韌體升級程式可以挖出寶嗎?
在網路上搜尋韌體更新。
在三星網站上只有最新版本。但是在網路上可找到其他版本。
EVO 840 250GB SSD韌體版本:
1: EXT0AB0Q (~2013-07) (原始韌體,在網路上找不到)
2: EXT0BB0Q (2013-10)
3: EXT0BB6Q (2013-12-18 19:43) (目前在三星網站可以找到)
4: EXT0CB6Q (2014-10-10 19:36)這包含在Samsung_SSD840EVO_Performance_Restoration.zip
5: EXT0DB6Q (2015-03-27 18:35)
下載了ISO映像檔來更新韌體,會得到個檔案類似這樣:
Samsung_SSD_840_EVO_EXT0BB6Q.iso
檔案裡面包含 isolinux/btdsk.img,可以透過 7-Zip 來解壓縮。在 btdsk.img 裡面有三個有趣的檔案:
samsung/DSRD/DSRDGUI0.EXE (韌體更新程式)
這個 EXE 檔案是用 WDOSX 打包並可以使用 WDOSXUnpacker 來解開 (要求要有 Python 2.7, 它不能在 Python3 環境下執行!):
https://raw.githubusercontent.com/0xDB/WDOSXUnpacker/master/WDOSXUnpacker.py
這個韌體會有兩個檔案:
samsung/DSRD/DSRD.enc (韌體更新組態檔)
samsung/DSRD/FW/ext0bb6q/EXT0BB6Q.enc (韌體本體)
解密到了一半,發現這一個工具,能夠將它們完全解密:
https://github.com/ddcc/drive_firmware/blob/master/samsung/samsung.c
這個混淆方式是在每個位元組中的高半字節的4位元加密。
試著反編譯韌體,但這種方法有幾個問題:ARM 有一個 Thumb 模式,這不同於 ISA(指令集架構),每個命令只有16位元,它可以在 ARM(32位元)和 THUMB(16位元)模式每次的跳轉/呼叫之間來回。所以它取決於編譯器想要生成什麼代碼,而且它很難猜到一個特定的 DWord,在實際上只是從原始二進制來的一個 ARM 指令還是兩個 THUMB 指令。一般的方法是獲取一個已知的入口點(假設 CPU 通常以 ARM 模式啟動,而不是以 Thumb 模式啟動),然後跟隨任何跳轉/呼叫,並從中了解目標點實際上是 ARM 還是 Thumb。但是,由於不知道在開始的地方有任何進入點,失敗。
可用 JTAG 介面透過韌體進行單步除錯檢測,並且無論是 ARM 還是 Thumb 都記錄每一步指令,然後將這些資訊從追蹤倒回反向組譯器以及反編譯程序,而這些記憶體區域包含 ARM 代碼或 Thumb 代碼。本次文章先不說明JTAG .
另一個問題是記憶體映射。韌體檔案由10個部分組成,這些部分被掛載到不同的記憶體區域,後來我發現其中一些被額外映射到其他範圍,這部分取決於它們正在運行的實際 CPU 核心。這個實際的映射也是有趣並有助於反組譯/反編譯它。
然後分析了韌體檔案的格式,發現它包含一個標頭,然後10個分區(好好地對齊及不重疊),最後一些數據在分區之外。之前的韌體版本具有非常相似的結構,只有幾個分區大小略微不同。
http://www2.futureware.at/~philipp/ssd/analyse/EXT0CB6Q.dec.html
SATA PHY
這個案例中 重點在於故障的SSD SATA PHY 無法通訊 回應為 BSY
在 SATA 協議中有各種超時,所以任何讀/寫一個區塊的請求都應該在幾秒鐘內完成,而不是幾分鐘。
在這樣的請求期間跟踪 SATA 控制器造成整體處理速度太慢。
而且當達到超時的時候,在一些情況下,電腦和 SSD 正在收到非常多的不同步訊息,以至於它們無法恢復通信,我必須透過手動切斷 橋接的電源來中斷 SATA 通訊。
所以除錯應用了類似DNA 類測測序方法:
設計了一個工作流程,從SSD中不斷的讀取單個扇區,每一個具有獨特的地址:
while true
do
dd if=/dev/sda of=/dev/null count=1 skip=1251255 #0x1317b7
#dd if=/dev/sda of=/dev/null count=1 skip=4235125 #0x409F75
done
在執行這個工作流程時,讓所有處理器核心運作。我隨機中斷一個核心,追踪和記錄 30 個指令,然後恢復核心運作,以便它可以滿足請求也還是兼容硬式即時。與基因測序類似,每次獲得30個指令的短片段,它們是隨機重疊的,這可能再次在一起難解。
一些基準:1指令:3秒(大部分在高點),10指令:5秒,30指令:12秒,100指令:31-44秒
有一件事情幫助很大,記錄每個指令的下一條指令實際上是什麼。所以它甚至可以使用單個指令片段。
因此執行工作負載和收集代碼片段,然後透過搜索了這些片段獲得用於讀取這些區塊的獨特地址,發現了它的一部分。
0x00000af8->0x00000afa Thumb Supervisor 0x00000af8 0x78c9 LDRB r1, [r1, #0x3] r1:0x00800D80=>0x00000025 r1:0x00800D80=>0x00000025 [0x00800D83]=1317b025
然後改變地址到一個不同的和獨特的地址,然後新的地址出現在相同的地方:
0x00000af8->0x00000afa Thumb Supervisor 0x00000af8 0x78c9 LDRB r1, [r1, #0x3] r1:0x00800DA0=>0x00000025 r1:0x00800DA0=>0x00000025 [0x00800DA3]=409f7025
LDRB 指令只加載一個位元組,但是追踪器總是從被訪問的記憶體位置讀取32位元(一個DWord)。所以在這裡不小心找到了扇區地址,並且 CPU 只對它旁邊的單個位元組感興趣,它最終是 SATA 請求命令位元組。
所以跟踪排序後,發現 SATA PHY 將請求的區塊地址交給 CPU:
0x00800DA0 似乎是傳入 SATA 請求的基底地址之一。
0x00800DA3 (base_addr+3) 包含一個帶有SATA請求命令的位元組。
一些重要的SATA指令:
0x25 讀取 DMA extended (LBA48)
0x35 寫入 DMA extended (LBA48)
0x92 下載 microcode (韌體更新)
0xb0 SMART
如果對SATA指令有興趣:
http://www.t13.org/
http://www.t13.org/documents/uploadeddocuments/docs2006/d1699r3f-ata8-acs.pdf
在各種序列中觀察到的一些基本地址
(strings debugmex* |grep 0x00000af8 |grep -v LDRB |sort |uniq)
0x00800C00
0x00800C10
0x00800C40
0x00800C50
0x00800C90
0x00800CB0
0x00800DE0
0x00800D60
0x00800DF0
0x00800E00
所以從 0x00800C00-0x00800E0F 的全部確定是 SATA 請求(也許範圍可能更大),會說整個 0x00800XXX 是潛在與 SATA PHY 有關的。另一件事告訴我們,這裡每個 SATA 請求大約只有16個位元組可以使用。
發現有 33 個 NCQ 暫存區的請求:
第一個暫存區從 0x00800C00 開始,第二個暫存區從 00800C10 開始…因此 0x00800DA0 實際上是第 26 個請求暫存區,最後一個暫存區從 0x00800E00 開始,結束於 00800E1F。並且每個請求暫存區是 16 位元組長,並且包含 SATA 命令、請求的地址…
甚至還有另一件事是,扇區地址實際上似乎不是由 mex1 讀取的,所以整個記憶體管理,磨損平衡,區塊重新定位和平排似乎是由不同的核心完成的。
所有這些地址絕對在 BTCM 範圍內(TCM=Tightly Coupled Memory,這是一個緊密接合到 CPU 的快速 SRAM,大多數 ARM 晶片有兩個 TCM 介面,命名為 ATCM 和 BTCM)
COMINIT/COMRESET
SATA PHY 通常是否自動初始/回應 COMINIT/COMRESET/COMWAKE 信號,或者 CPU 是否必須向 SATA PHY 發送信號。
。
最後,結果證明 COMINIT/COMRESET 必須用 CPU 發出信號,mex1 與它有關聯: 試著觀察當 SSD 只通過電源連接但沒有透過 SATA 資料線去溝通時發生了什麼事,
而發現 SSD 狀況應該是這樣的:
狀況圖:
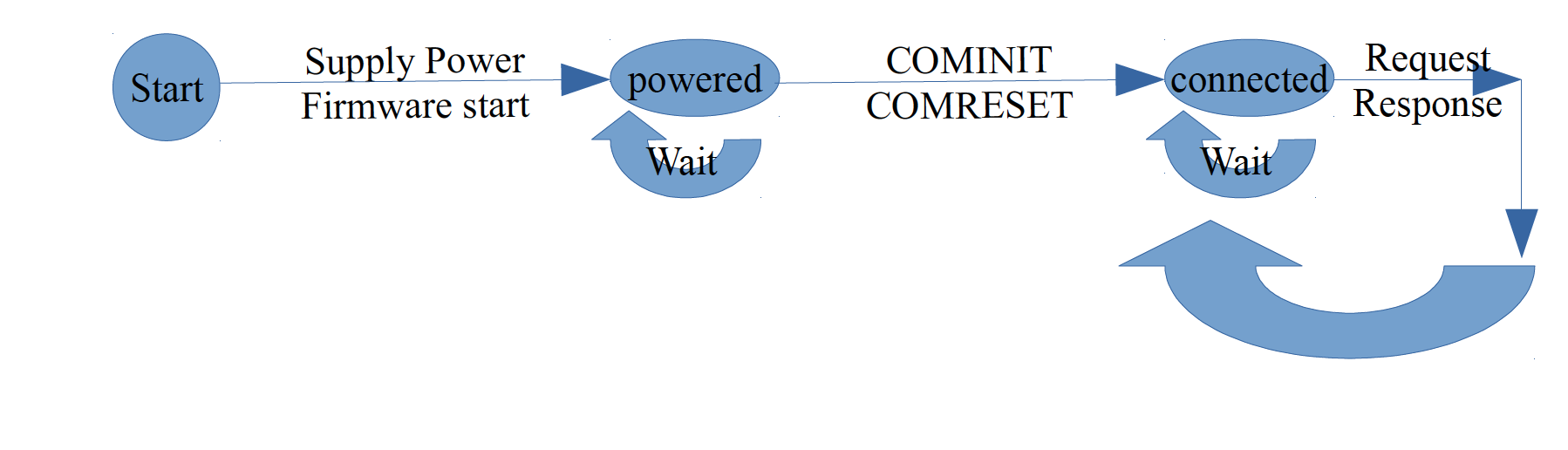
一旦 SSD 連接電源,它會啟動韌體,當初始化完成後,它開始等待與 HOST 電腦的連接(一個小的循環來檢查狀態寄存器, 0x200000AC 位元為 COMINIT 信號),當發送那個信號則透過配置用於連線的 SATA PHY 來繼續,然後它開始等待來自電腦的請求。
這故障 SSD 狀況可能為 ,啟動後應該正確地初始化 SATA PHY,但它之後以某種方式偏離正確的程式流程,並且沒有到達“供電等待” (ATA Ready ) 的迴路。如果韌體進入“供電等待”迴路,它可以從 SATA PHY 獲得 COMINIT 信號並可以正常的繼續下去。
那麼是在哪裡又為什麼他會不正常啟動?在程式流程中可能的分支導致 SSD 損壞是在哪裡?
SAFE MODE UART
在安全模式下可用的 UART 介面具有 3.3 Volt FTDI RX/TX 針腳,並使用 115200 8N1 的設置。
它被設計來用在特殊目的的 SSD 除錯程式,。
它有十幾個命令,唯一分析一個是“r”命令,它可以用來從記憶體中讀取資料。
用“HDD Serial Commander”的工具 http://www.hddserialcommander.com/,一旦我們找出了這些命令,它應該提供一個GUI。 (指令必須插入到 SQLite 資料庫中)
從CPU端,可以通過以下方式連接 UART:
UART基址:0x20503000
從 UART 讀取一個位元組:[0x20503018]:串列位元組 IN
向 UART 寫入一個位元組:[0x20503014]:串列位元組 OUT(必須至少向該暫存器寫入16位元,但串列線上只能寫入8位元)
每次讀/寫的操作後,韌體代碼在一個迴圈中等待大約 50 個 CPU 週期。你可以在這裡看到通信模式:
http://www2.futureware.at/cgi-bin/ssd/logs?log=debugmex1-safe-press-r-UART_REGISTER.log(在該頁面上搜索UART)
JTAG
做完JTAG 發現
mex1負責通過SATA接收數據
mex3負責與NAND閃存通信,其中存儲實際數據
mex2負責通過SATA回复
對於從SSD讀取或寫入扇區,順序如下:1-> 2-> 3或 1→3→2。
所以mex1必須先來(解析SATA請求),然後2和3必須後來,
SSD這種高速需求當然會要這3個任務可以並行處理
正確的SSD初始化是怎樣的?
一個SSD能正常工作 其初始化過程。由幾個階段組成。
- SSD 將韌體部分從處理器中的內部Mask ROM 加載到 RAM,並繼續執行(Bootloader)。
- 記憶體晶片測試。
- SSD 讀取在Flash韌體加載到 RAM,並執行 RAM中的Kernel 。
- SSD 讀取Flash中的組態頁缺陷表生成編譯器。
- SSD 讀取組態頁其他部份。
如果上述所有階段都成功通過,SSD 將回報就緒狀態,回傳其標識數據(型號,容量,序號等),並允許存取資料。通常,儘管它可能具有使資料存取複雜化的檔案系統錯誤,這種 SSD 還是可以操作的。
Mask ROM 與安全模式
SSD SOC 只有載入 SOC 內的ROM 而沒有載入在Flash 上的完整韌體的狀況被稱為安全模式。在安全模式下,磁碟只支援幾個 ATA 命令。通常,它們包括 ID 讀取命令(0xEC)和載入韌體(0x92)的命令。
磁碟可以通過在板上連接某些觸點來切換到安全模式。
當無法從記憶體晶片載入主要韌體時,磁碟也可能由於故障而在安全模式。
要強制磁碟進入安全模式,必須關閉電源,連接板上相應的短路點,然後打開電源,等待磁碟回報準備就緒。如果磁碟在10秒內沒有達到ATA就緒狀態,表示選到了錯誤的短路點,或者可能代表磁碟(RAM,處理器,電源的子系統)的物理故障。請注意到如果記憶體晶片損壞,磁碟通常會在安全模式下達到準備就緒的狀態。磁碟回報就緒之後,再移開短路的工具。
部分三星 SSD 系列中短路的正確接觸點:

圖1 MLC SSD

圖4 840系列
請注意,有時候您可能會遇到使用跟上述標準板的佈局不同的電路板。在遇到這些 SSD 的情況下,可以使用幾種方法來進入安全模式:
第一種方法適用於MLC SSD(S3C29RBB01-YK40 控制器)。這些 SSD 中的主韌體存在Zero Channel bank Flash中。
短路第零儲存庫並橋接資料線路,就會讓控制器讀不到主韌體 .因此 SSD 將保持在安全模式。
Zero Channel bank flash 可以通過連續檢查晶片來識別。一般情況下,它在控制器附近。可以使用晶片的文件來判斷晶片資料線的位置。
讓以一個三星 MMCRE28G5MXP-0VB SSD為例見圖。
磁碟是 MLC SSD 系列。它已經焊了標有 K9HCGZ8U5M-SCK0 的 TSOP-48 晶片。

圖5 TSSOP-48 晶片資料圖
在 TSOP-48 的敘述中,我們可以了解 DQ0-DQ7 代表資料線。因此,您可以通過短路任何一對接點來強制 SSD 進入安全模式。
(這個方法思路同於2016 Defcon 縫衣針破解Router法)

圖6 MLC SSD 上 DQ6 與 DQ7 線的接點
第二種方法適用於470、830和840系列的 SSD。仔細觀察任何一款這類 SSD 的電路板,可以看到連接點旁邊有一個10針檢測連接器的接觸點。例如,請參見840系列 SSD 的電路板(見圖4),說明了連接點和連結電路板之間的關聯(見圖7)

圖7 PCB連接點和檢測連接器的連接盤之間的對應位置
可能在其他SSD系列看過類似的圖片。可以通過橋接10針檢測連接器的連接點 1 和 2 來進入安全模式 ,此為專用安全接點。
假設不知道安全模式啟動方法的 SSD(例如,來自 Dell 筆電的 mSATA 830 系列)來測試這個假設(見圖8)。

圖8 Dell mSata
接觸點可以明顯的識別。6 一直是接地,您可以使用電錶來測量。一旦找到 6 號接點,就可以準確的識別剩餘接點的位置。短路 1 跟 2 接點就能進入安全模式
主韌體
三星 SSD 的主要韌體部分儲存在Flash 中。 某些MLC SSD 在零通道的第零儲存庫中只有一個主韌體體並無副本。
470 系列的 SSD在零通道上的各個初始4個儲存庫中保存4個主韌體副本。 830 和 840 系列的 SSD 還有4個副本的主韌體儲存在零通道的前兩個儲存庫中。
Microcode 由幾個校驗法保護著。它們通常使用在載入和更新硬碟韌體時由韌體從遮罩 ROM 驗證SHA(安全散列算法),CRC(循環冗餘校驗)或DSA(數字簽名算法)的變化。如果校驗碼驗證成功,則將控制權遞給主韌體。不然的話,磁碟會保持在安全模式
組態參數(Config Page CP)
組態參數是代表磁碟用於儲存不同配置,例如SSD ID Model、密碼資訊、最大LBA設定、S.M.A.R.T. 記錄等 分類方法跟磁碟模塊一樣。
三星 SSD 在最大 LBA 之後的區域或在佔用每個記憶體晶片開始處的空間的服務區中儲存СР。它們不會明顯的影響硬碟運作,但它們可能會影響到使用者資料的存取。例如,如果隨機數據在包含密碼資訊或最大LBA中出現,就可能會發生這種情況。
Loader
三星 SSD 允許將外部韌體載到 RAM 而不是從Flash 晶片載入。
當主韌體被破壞或者由於記憶體晶片的問題而不能被載到 RAM 時用於偵錯會非常方便的功能。此外,我們將韌體直接上傳到 RAM 稱為載入器。
載入器可以具有比儲存在記憶體晶片中的主韌體更多的功能。因此,三星 SSD 工具可以在轉譯器損壞的情況下以«原始»格式讀取晶片內容,可以存取密碼保護 SSD 上的資料等。
磁碟初始化期間的錯誤
讓我們回顧一下三星 SSD 初始化過程中錯誤相關的可能性問題。這樣的問題通常導致不能使用邏輯坐標來存取使用者的資料。初始化錯誤可以被細分為以下幾種類別:
- SSD 無法達到就緒狀態。
- SSD 準備就緒,但無法回報Device 型號ID。
- 在設備ID回報«ROM MODE»而不是其型號。
- 回報 SSD 容量為零或只有幾MB。
- 在嘗試讀取資料時發生錯誤。
磁碟無法進入就緒狀態
這有好幾種可能的原因,主要有下面幾個:
- 損壞的 PCB 元件
- 控制器損壞
- RAM 損壞
- 記憶體晶片有一個或多個損壞
- 編譯器中有錯誤資料
首先,您必須對SSD做目視或是電壓檢查。如果電路板上有缺陷或損壞的元件,必須將它們換掉。然後將SSD切換到安全模式。
如果SSD無法進入安全模式,有可能是控制器或 RAM 出現故障。
如果SSD進入安全模式,啟動載入器並執行記憶體晶片測試。如果晶片測試沒有顯示任何問題,那或許是轉譯表的損壞。
磁碟準備就緒,但無法回報 ID
此問題通常在 MLC SSD 遇到。這是因為 SSD 無法從記憶體晶片讀取主韌體,使其留在安全模式。因此,這意味著通道0的零儲存庫或主韌體已經損壞。
在設備ID回報«ROM MODE»而不是其型號
通常是在 470、830 和 840 系列的硬碟會遇到此錯誤。來自這些SSD Soc內建的ROM 韌體具備更廣泛的功能,並且支援讀取設備ID(0xEC)的命令。 «ROM MODE» 中的 ID 特別標明了硬碟正在安全模式中。
錯誤造成:
零通道的損壞晶片
全部副本 都是壞的韌體
回報磁碟容量為零或只有幾MB
這是三星 SSD 上最常見的損壞。它或許是以下兩個原因造成:
主韌體損壞
組態參數(CP)損壞
如果發生這個錯誤,請使用韌體更新程序。在韌體更新期間,某些組態設定也會更新或驗證。如果 CP 中有錯誤,它們會被修正。如果問題是由韌體中的錯誤所造成,透過更新也會消除該問題。
在嘗試讀取資料時發生錯誤(Error return)
這個錯誤或許是由下面的情況造成:
- SSD 有密碼保護
- CP組態頁面損壞
- Translator 編譯表損壞
必須檢查 SSD 是否啟用了密碼保護 使用一般程式(hdparm 就可以檢查是否有ata加密)
若沒有加密 則很有可能就是CP 或是編譯器表損壞
結論
這個案例Philipp Gühring並沒有維修成功,根據OSSLab經驗,藉由PC3000 SSD設備這還算很容易處理的.
但是目前SSD與Flash資料救援的難度最主要在於.
1.未知XOR 像Sandforce 不同廠商會給不同Xor 密鑰.並且全球只有俄羅斯BVG公司提供此主控資料恢復.價格不便宜
2.狀況很糟的TLC.非常容易損壞. 或是要拆下多次讀取,要不然恢復難度很高.
3.不支持的主控 .與特別OEM 密鑰.
4.PCI-E主控開始流行.恢復狀況更複雜
技術問題要基於根本狀況,來慢慢抽絲剝繭一步步解決.
