
文章摘要
本文由微軟事件回應團隊撰寫,深入分析 LockBit 2.0 勒索軟體中的程式碼漏洞。某客戶支付贖金後,發現關鍵 MSSQL 資料庫仍無法解密。透過
Procmon 監控和 TTD 逆向工程分析,研究人員發現加密器未正確處理 NTSTATUS 回傳值,尤其是
STATUS_PENDING,導致非同步寫入操作出現錯誤。最終透過重新對齊解密斑塊(blob)位置,成功恢復資料庫檔案。
這篇是客戶 LockBit 2.0 付款贖金後,還是無法完整恢復重要數據,微軟事件團隊分析後發現是加密時候就有 BUG。
本文轉自: Microsoft Security Experts Blog
研究人員:Nino 和 Team Torstino(Microsoft 事件回應)
免責聲明:本文所包含的技術資訊僅供一般資訊和教育目的,不能取代專業建議。
LockBit 2.0 勒索軟體是過去 2~3 年來主要的勒索軟體病毒之一。最近,FBI 發布了一份緊急警報,概述了 LockBit 2.0 聯盟之「勒索軟體即服務」(Ransomware-as-a-service) 相關的技術方面以及策略、技術和程序 (TTP)。
可以說,圍繞該勒索軟體的大量詳細研究是在 2021 年夏天出現的「2.0」版本中出現的。然而,所有這些公開報告和技術承諾,都沒有提到微軟事件響應團隊研究人員發現的勒索軟體之一個關鍵方面:「錯誤代碼」以及不可預測的誘導後果。
這篇文章展示了針對 MSSQL 資料庫的勒索軟體復原的直接嘗試,其中我們發現並進一步利用 LockBit 2.0 勒索軟體程式碼中存在的 Bug,直到我們能夠恢復這些資料庫檔案的加密過程,並恢復它們回到正常運轉狀態。
背景
在與遭受到 LockBit 2.0 影響的客戶首次互動時,我們發現到該勒索軟體邏輯的嚴重不一致,該客戶有購買號稱可恢復勒索軟體造成的損壞,並將勒索軟體所加密的檔案還原。
但不幸的是,這位客戶很快就發現,基於勒索軟體聯盟的「傳播商」所聲稱的支付贖金決心,獲得能解密的說法非常可疑。在嘗試使用購買的解密工具來恢復關鍵資料庫檔案時,客戶得到了非常令人失望的結果無法順利解密。
針對此事,微軟事件響應團隊與該客戶進行了接觸,獲得了勒索軟體加密器和解密工具方面的存取權限,並懷疑「錯誤的加密」正在發揮作用,因此開始進行分析。
我們對加密器的觀察並識別其異常情況
當懷疑有錯誤的加密/解密時,為了讓我們的生活更輕鬆,我們可以做的第一件事之一,就是首先避免深入研究任何有關密碼學的密集遲鈍方面的文獻。相反的,使用 Sysinternals 方便的 Procmon 工具,其提供監視檔案 I/O 的功能,希望在加密器或解密器運作時,可發現任何類型的異常或不一致。
透過這種監控,我們應該快速並正確了解加密/解密演算法是如何實現的。
例如,圖 1 顯示了加密器在我們建立的測試虛擬檔案上的運作情況。值得注意的是,當假設有錯誤的加密演算法在起作用時,要測試各種檔案大小,看看它們如何/是否會產生不同的結果。

圖 1. 運行中的加密器測試 #1
測試 #1:進階觀察
- 它會增加檔案長度
- 它只加密從標頭開始處開始的前 0x1000 位元組(理論上,足以覆蓋掉任何標頭的元資料)
- 在原始檔案大小(0x200 位元組)的末尾附加一些數據
- 把 .lockbit 副檔名附加到原始檔名
總結:它附加到加密檔案末尾的資料,是解密工具在復原過程中所需使用到的解密資訊。每個檔案都使用唯一的 16 位元組初始化向量 (IV) 和 AES256 金鑰進行加密。
測試 1GB 檔案是一個好的開始,但讓我們嘗試一個更大的文件,然後再次透過 Procmon 觀察加密器的行為。
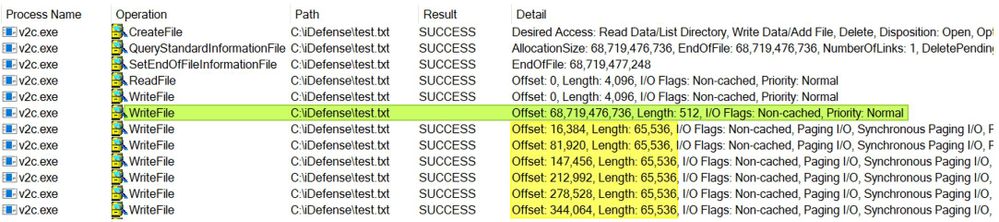
圖 2. 運作中的加密器測試 #2
測試 #2:進階觀察:
- 開始就像我們的第一次測試,但結束時卻截然不同
- 奇怪的是,在附加「解密 blob」時,Procmon 不會為 WriteFile 作業產生結果
- 它似乎以 65,536 位元組的間隔進一步加密更多數據
與我們的第一次測試有一些明顯的差異,第二次測試引起了我們足夠的興趣,讓我們繼續深入挖掘。
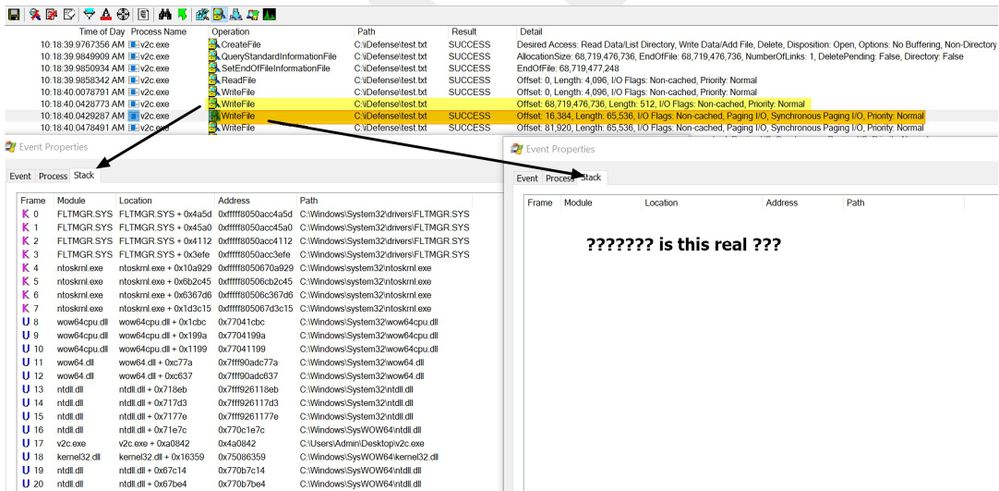
圖 3. 查看 WriteFile 操作的呼叫堆疊
黃色突出顯示行中的空結果後面的每個 WriteFile 操作看起來都像右側的“事件屬性”框:空。這確實很奇怪,需要比 Procmon 給我們更深入的反思。在偏移量 +0xA0842 處,我們可能永遠不會回來。
現在感覺是時候介紹我們最喜歡的工具集,來進行深入的故障排除:Time Travel Debugging 逆向工程(TTD)
究竟是什麼問題?
在引入 TTD 框架之前,我們首先將加密器載入到 IDA Pro 中,並前往 Procmon 識別的偏移量以觀察該位置的程式碼。
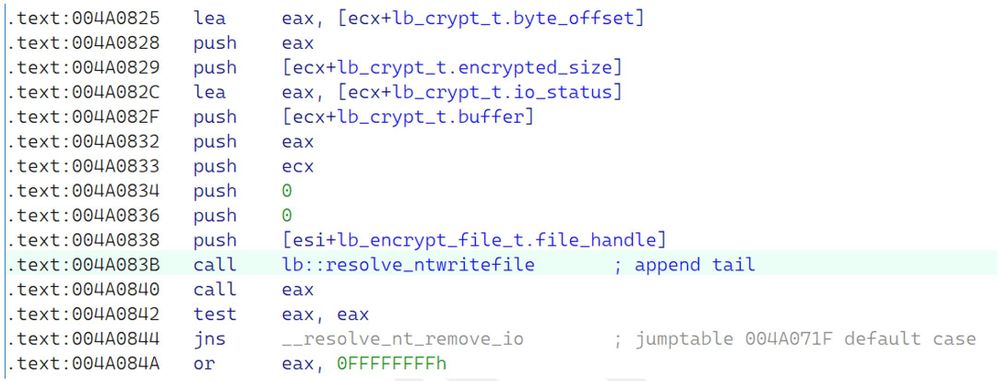
圖 4. 負責將加密內容寫回磁碟的程式碼
我們也展示了這段程式碼的清理反編譯,以便在更高的層級進行觀察。

圖 5. 圖 4 的反編譯
如圖 4 和圖 5 所示,我們可以發現這裡有些不對勁;寫入檔案的 NTSTATUS 回傳值未正確處理。事實上,這是完全錯誤的。
但如果我們深入研究 IDA 內部的二進位文件,我們就可以確認加密器的非同步性,這是透過 I/O 完成連接埠實現的。
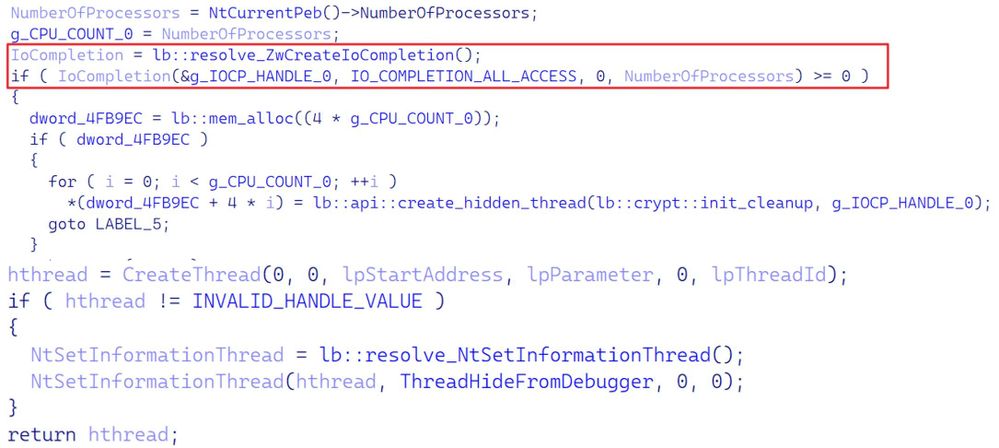
圖 6. 加密器多執行緒初始化並使用執行加密的隱藏線程
對 NtSetInformationThread 的呼叫所做的是,在內部執行緒結構中設定 HideFromDebugger 標誌,這保證了偵錯器永遠不會收到該執行緒的任何偵錯事件。
NTSTATUS 值問題
首先,LockBit 2.0 開發人員錯誤地假設所有不成功的 NTSTATUS 值都已簽署。考慮到加密器的異步行為,以下這些與加密器非常相關,並且顯然不是負數:
STATUS_PENDING (0x00000103)STATUS_SUCCESS (0x00000000)
其次,更重要的是,它們完全忽略了待處理 I/O 操作的處理:STATUS_PENDING。鑑於 Windows 上 I/O 的非同步特性,理論上這可能是每個檔案 I/O 操作。
不這樣做將導致不可預測且可能具有破壞性的行為,因為當傳回值未簽署時,LockBit 2.0 會錯誤地認為每次寫入作業後都會成功。
關於損壞的解密工具(以及無法解密的檔案)
現在已經確定了至少一個可能導致加密錯誤的關鍵缺陷,讓我們將注意力轉移到解密過程本身。
客戶向我們提供了幾個 MSSQL 加密資料庫文件,這些文件有可能被正確解密。我們之所以可以做出這樣的聲明,是因為所需的解密資訊在文件中的某處仍然完好無損。
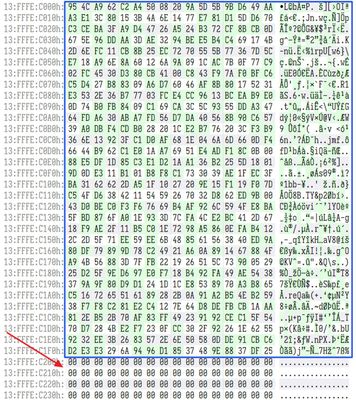
圖 8. 找到了解密斑塊(blob),但它不像應該位於檔案的末端/尾部
透過查看產生的追蹤文件,我們能夠確定解密工具現在確實正確找到解密斑塊(blob),而且能夠成功解密它,以獲取解密所需的 IV 和 AES 金鑰。但是,該文件仍然沒有被解密。
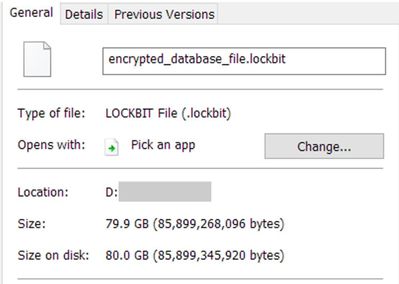
圖 9. 文件大小和我們正在處理的加密資料庫文件
根據 TTD 跟踪,簡單地切斷解密斑塊(blob)後面的所有資料也不起作用,但我們可以找出問題所在,甚至可以發現解密斑塊(blob) 最初應該在的位置。
意識到這一點,我們決定將解密斑塊(blob)「推」到其正確的偏移量,然後再次切斷其後面的所有數據。
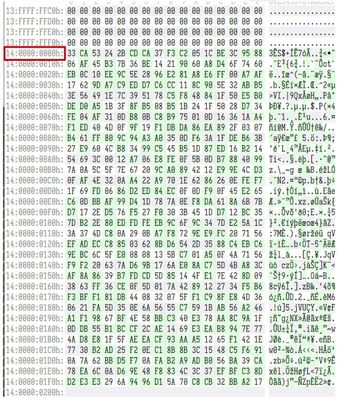
圖 10. 在重新運行解密器之前正確對齊解密斑塊(blob)
這次運行解密器後,我們成功解密了檔案!
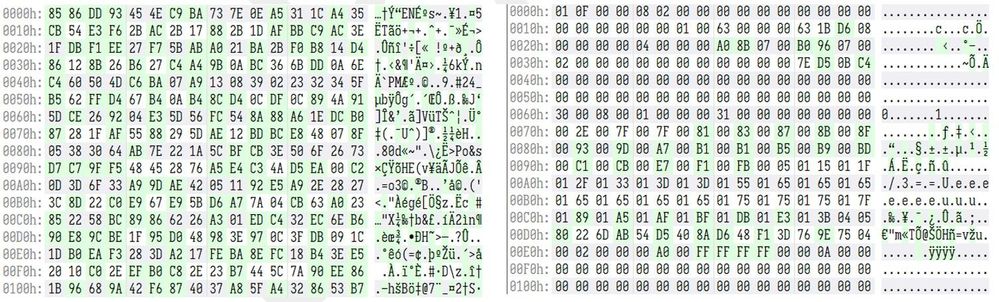
圖 11. (左) 加密檔案;(右) 成功解密文件
結論
雖然這具有某種成功的欺騙性外表,但我們必須始終認識到加密器內部的致命錯誤。這些勒索軟體開發人員的關鍵缺陷,在於誤解了 NTSTATUS 值的工作原理,以及它們對簡單線程同步可能產生的後果。
需要資料救援協助?
如果您的企業遭受勒索軟體攻擊,或有 MSSQL 資料庫復原需求,歡迎聯繫 OSSLAB 資料救援團隊進行評估。
