管理介面IP與帳密列表:
檔案伺服器連線方式與管理IP帳密:
用戶端連線方式: \\192.168.168.207\vol2\nas
連線IP: 第一組控制器 : 192.168.168.207
第二組控制器 : 192.168.168.214
因此可知 vol2 磁碟卷 是主要救援的目標
■ 救援分析動作
先檢視原始硬碟狀態
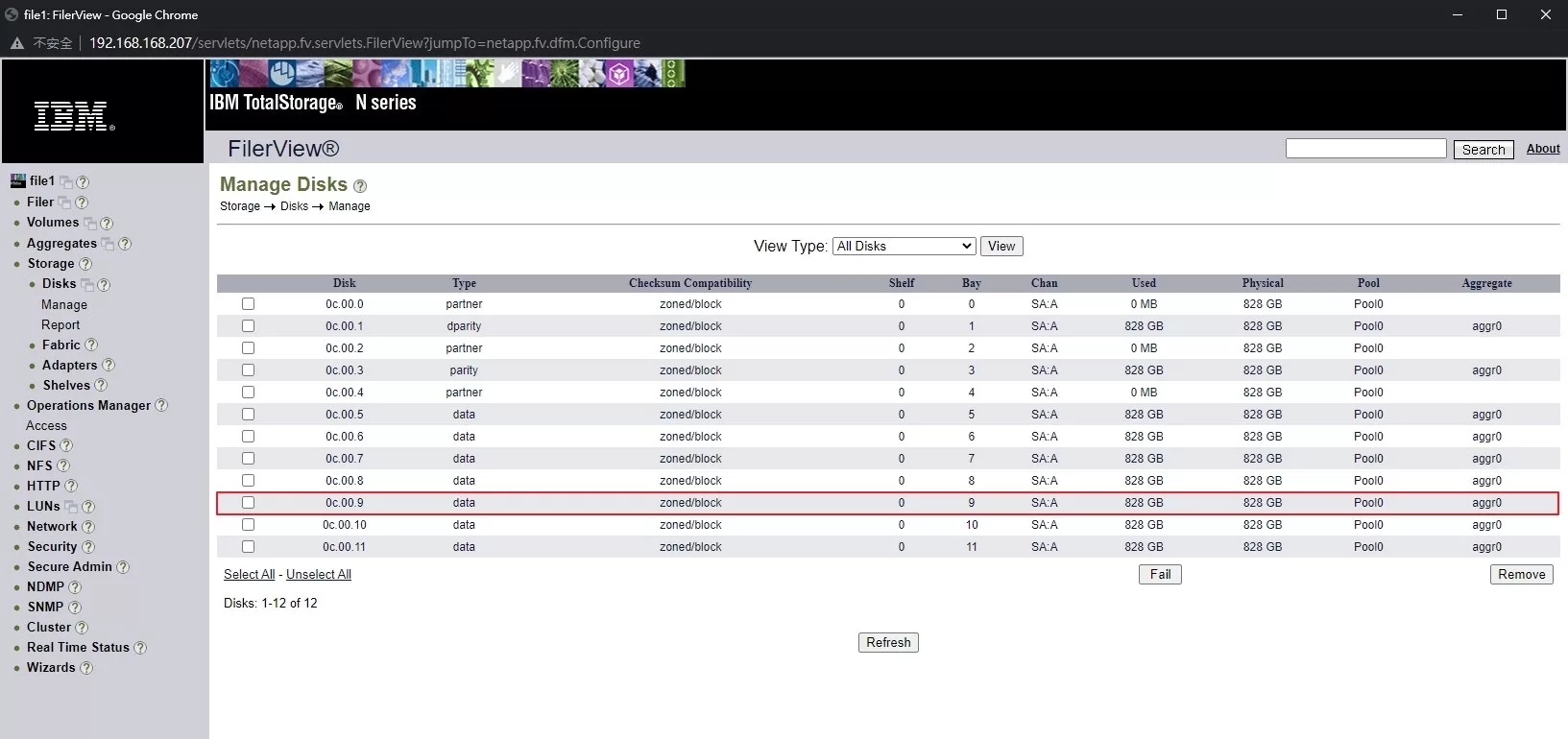
 ▲ 透過IBM的ONTAP 7.x管理介面,檢視目前 Disks 分配狀況 (0c.00.0 ~ 11),有9顆分配給aggr0
▲ 透過IBM的ONTAP 7.x管理介面,檢視目前 Disks 分配狀況 (0c.00.0 ~ 11),有9顆分配給aggr0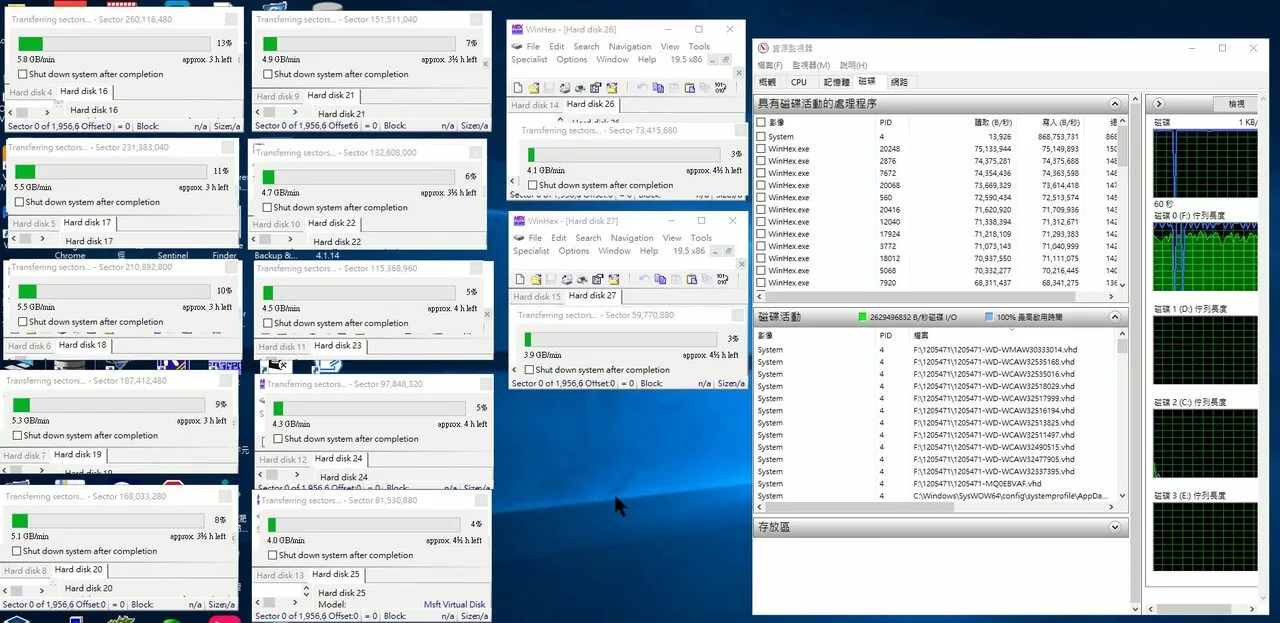 ▲在進行資料救援前,先將那12顆硬碟取出,進行鏡像(mirror),以保留資料原始狀態
▲在進行資料救援前,先將那12顆硬碟取出,進行鏡像(mirror),以保留資料原始狀態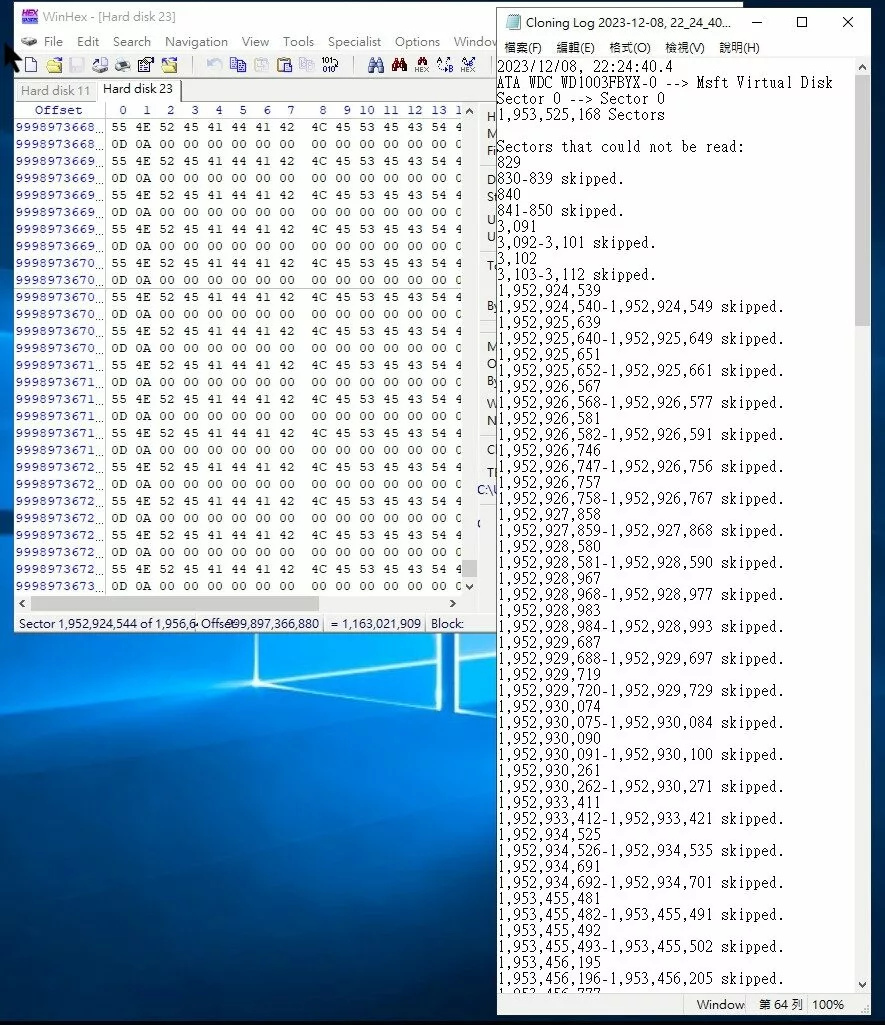
▲鏡像過程中,發現有部份硬碟的狀況不好,有壞軌
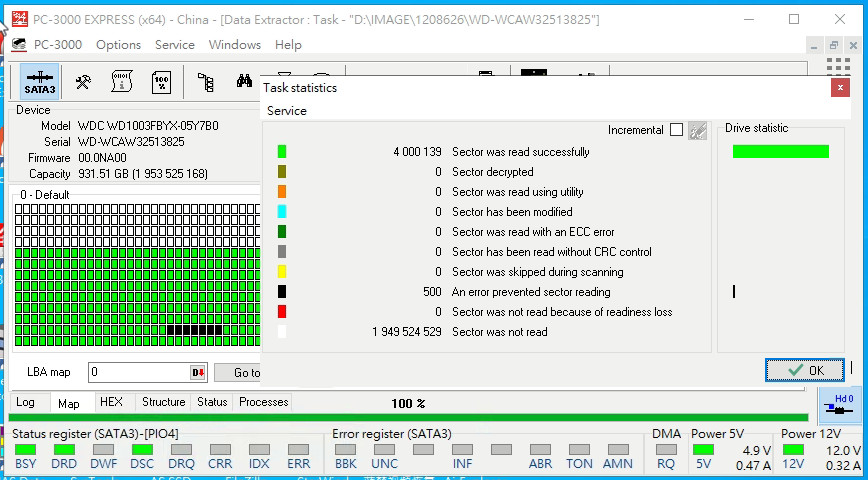
▲以專業的PC3000 低階硬碟資料工具,檢視硬碟的壞軌情況。
分析後,發現硬碟中,狀況極差的有: 1 & 3
因此第一次 mount 時,先把 disk 3 offline
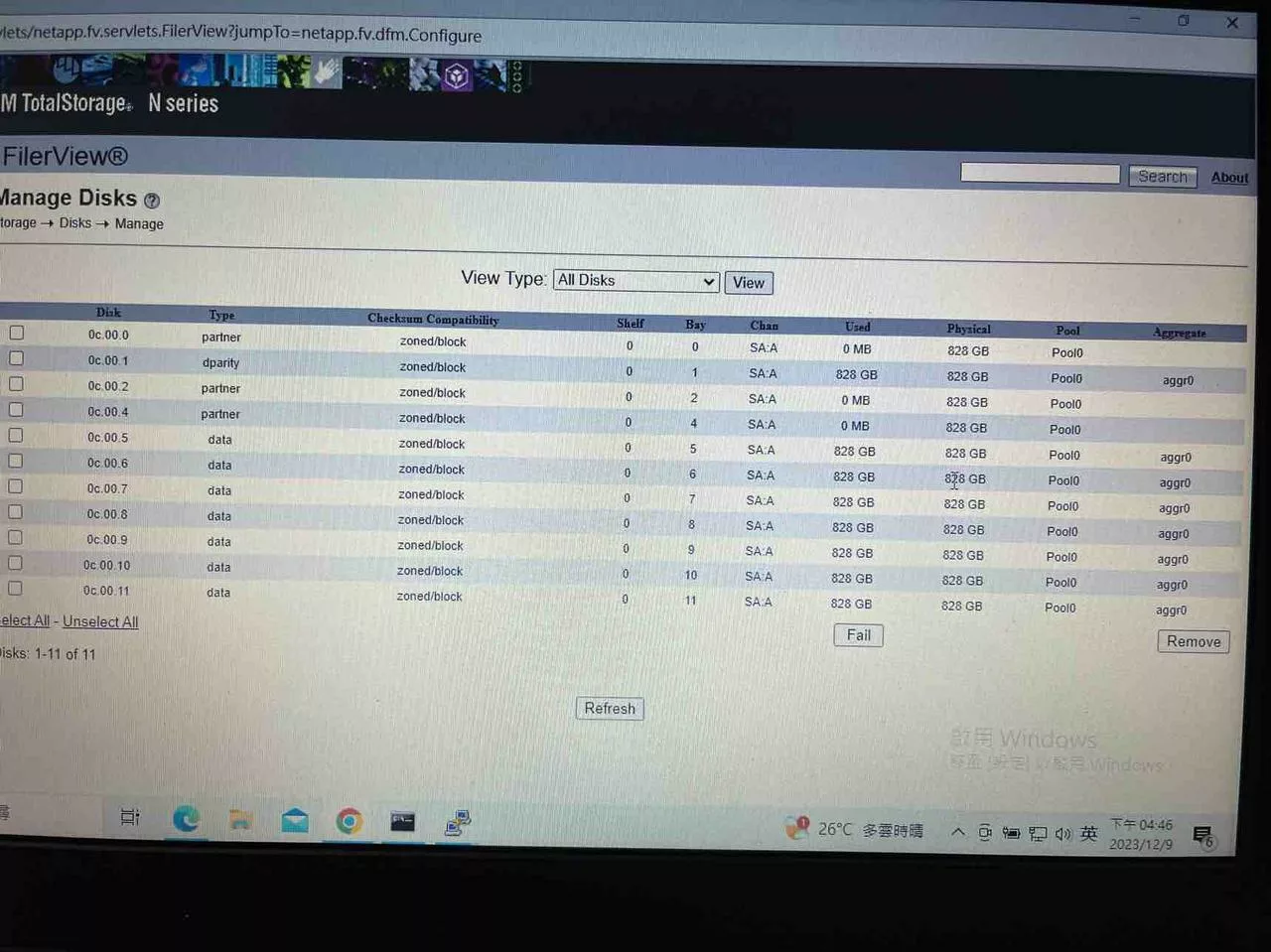 ▲ 取下 Disk 3之後的 Disks 狀態
▲ 取下 Disk 3之後的 Disks 狀態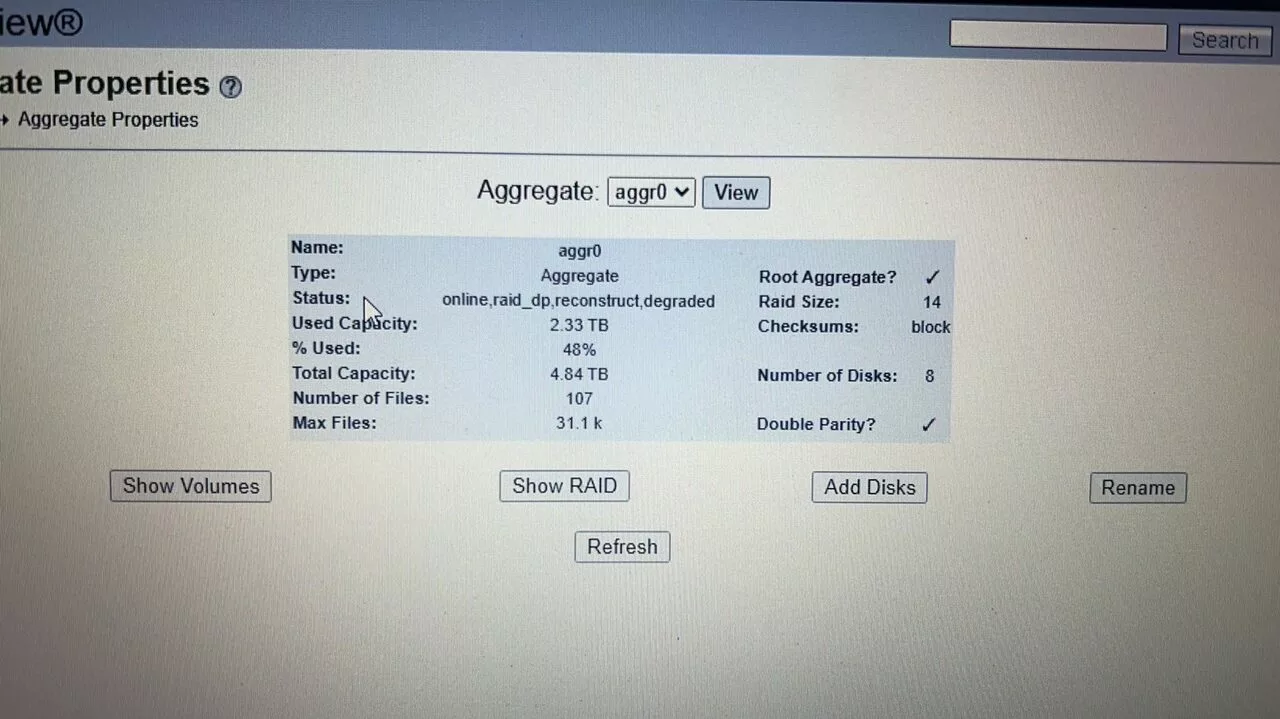 ▲ 取下 Disk 3之後的aggregate 狀態,aggr0 配置共8 Disks,佔用4.84TB,使用掉48%空間 (2.33TB)。可以看到使用掉的空間比之前全部硬碟都online時,增加了一些使用空間
▲ 取下 Disk 3之後的aggregate 狀態,aggr0 配置共8 Disks,佔用4.84TB,使用掉48%空間 (2.33TB)。可以看到使用掉的空間比之前全部硬碟都online時,增加了一些使用空間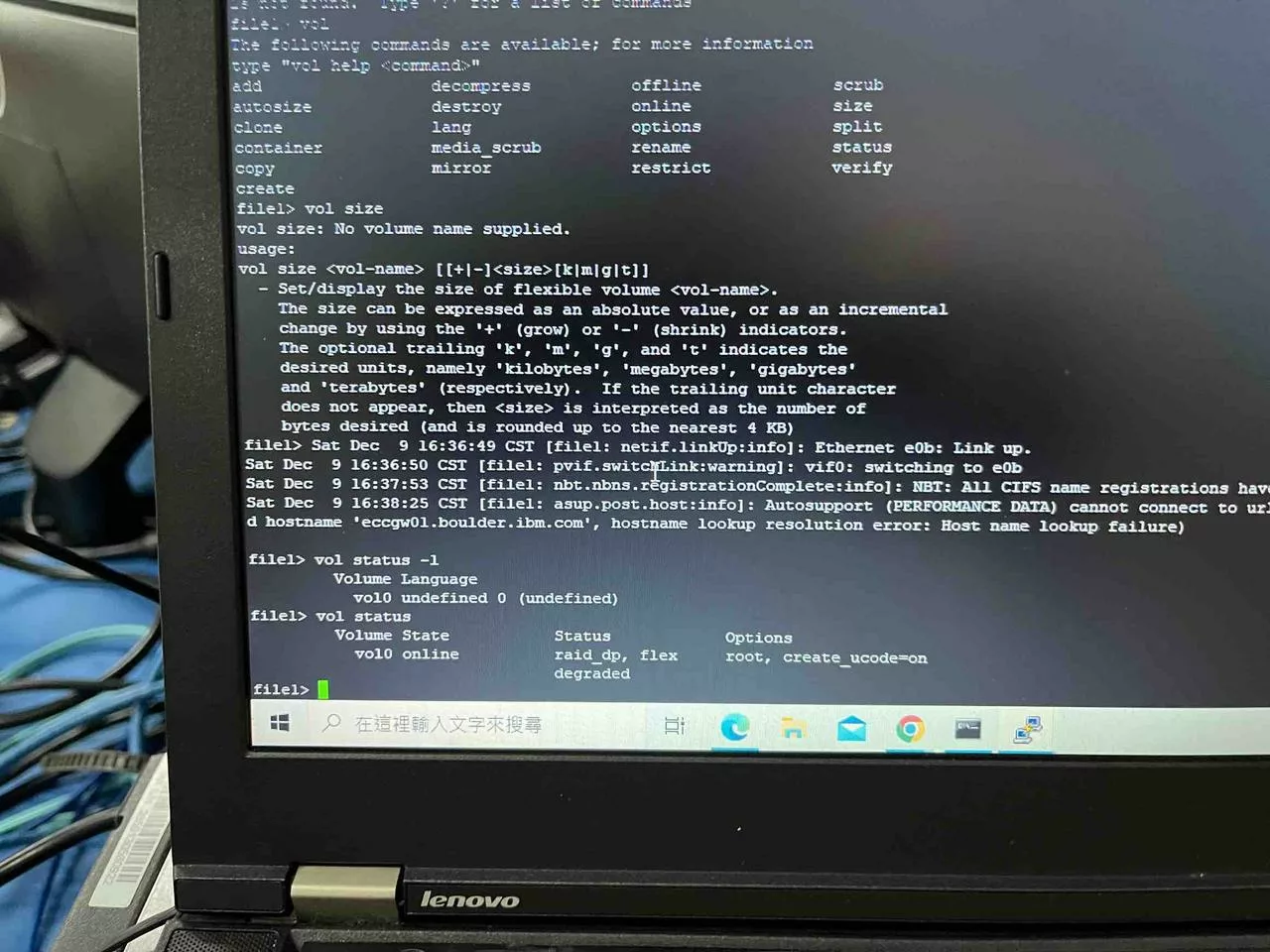 ▲ 嘗試檢視Volume狀態,僅找到 vol0 磁碟卷上線中,RAID組態已降級 (degraded)。並未發現 vol2
▲ 嘗試檢視Volume狀態,僅找到 vol0 磁碟卷上線中,RAID組態已降級 (degraded)。並未發現 vol2上線 missing
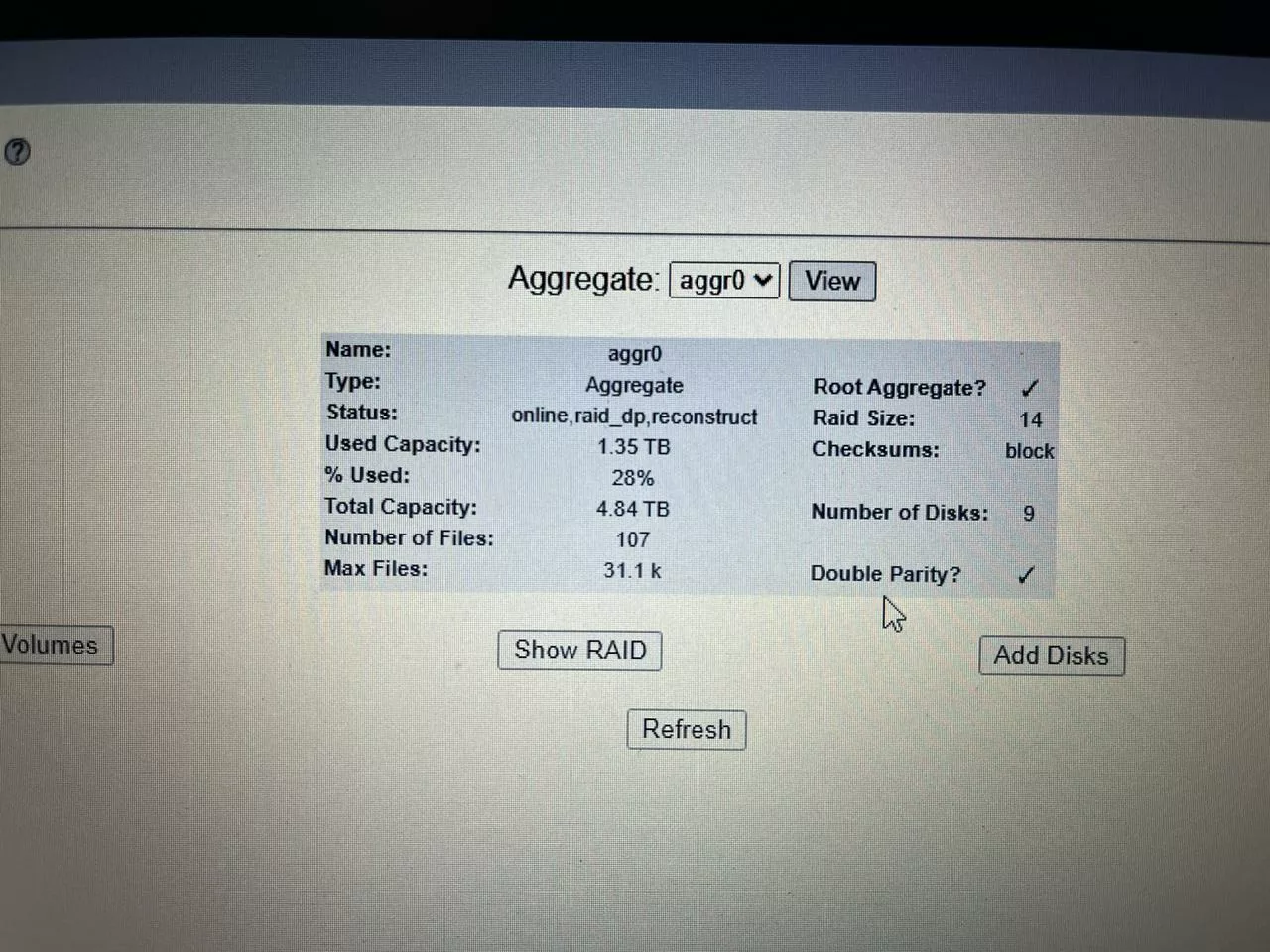 ▲ 再檢視 Aggregate裡的 aggr0 細節,可看到共有 4.84TB容量,使用掉 28%的資料量 (1.35TB)
▲ 再檢視 Aggregate裡的 aggr0 細節,可看到共有 4.84TB容量,使用掉 28%的資料量 (1.35TB)■ 救援分析結論
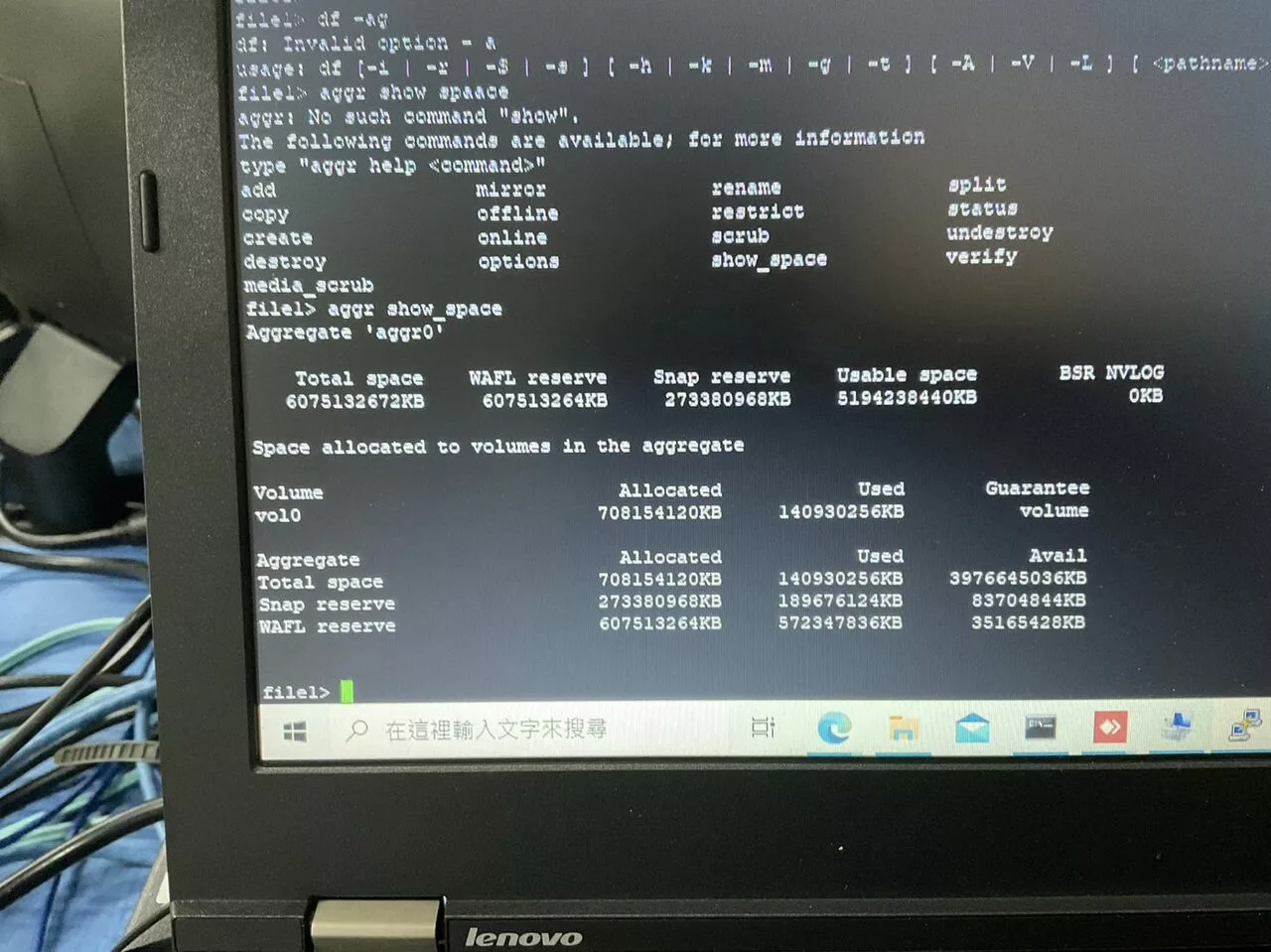 ▲ 再嘗試檢視 Aggregate 的配置細節,總容量為 6,075,132,672KB (5.65TB),其中NetApp專屬WAFL檔案系統保留區佔用607,513,264KB (580GB)、快照保留區佔用273,380,968KB (260.7GB),可使用的空間剩: 5,194,238,440KB (4.84TB)。該空間配置給 vol0 約 708,154,120KB (675MB),因此剩下3,976,645,036KB (3.70TB)的空間。與上面aggr0截圖的2.33TB相比,發現有1.37TB的空間是沒被看到的,這應該是 vol2 所佔用的地方。
▲ 再嘗試檢視 Aggregate 的配置細節,總容量為 6,075,132,672KB (5.65TB),其中NetApp專屬WAFL檔案系統保留區佔用607,513,264KB (580GB)、快照保留區佔用273,380,968KB (260.7GB),可使用的空間剩: 5,194,238,440KB (4.84TB)。該空間配置給 vol0 約 708,154,120KB (675MB),因此剩下3,976,645,036KB (3.70TB)的空間。與上面aggr0截圖的2.33TB相比,發現有1.37TB的空間是沒被看到的,這應該是 vol2 所佔用的地方。因此可分析出,aggregates (aggr0) 的紀錄那邊,那1.37TB的空間是有被佔用,而volumes的紀錄,原先預期應該有vol0 和 vol2 兩個磁碟卷宗,檢測研判可能因為硬碟壞軌,而導致 vol2 的磁區資訊無法正常顯示。經查看硬碟扇區,發現vol2 區有資料存在,如下圖紅框所示

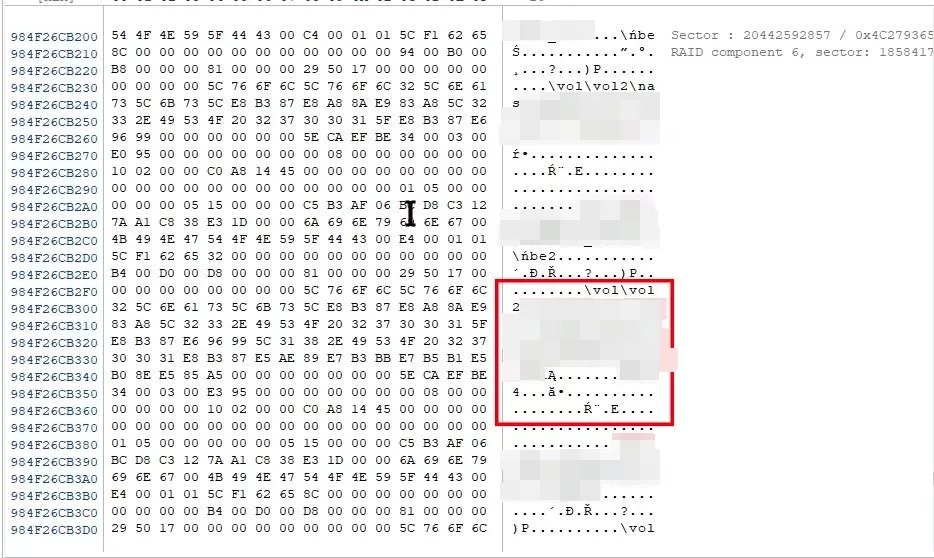
▲使用專業RAID組合軟體查看底層扇區依稀有發現vol2蹤跡
■ 以控制器救援作法
救援目標,嘗試將 vol2 所佔用的磁碟區導出,或嘗試修復 vol2的檔頭辨識區 (magic number),讓系統可以抓到該磁碟卷宗。若無法修復,就得透過掃描重組的方式,嘗試將資料導出,先將原硬碟狀態先做鏡像。
目前已知, disk1 、disk3硬碟有嚴重壞軌,則disk0在機器上顯示有故障狀況,在Aggregate 介面中,硬碟資訊有顯示重新建構(reconstrust)中,因擔憂壞軌導致vol2遺失,故將原始12顆硬碟資料倒回原硬碟,以及嘗試使用同型號硬碟將上述嚴重壞軌硬碟替換掉,以驗證是否能掛載並使用搜索方式將vol2做數據恢復,或使用使用專業數據恢復軟體重新組合RAID後將資料導出。
此方法失敗
